

| Organism | |||
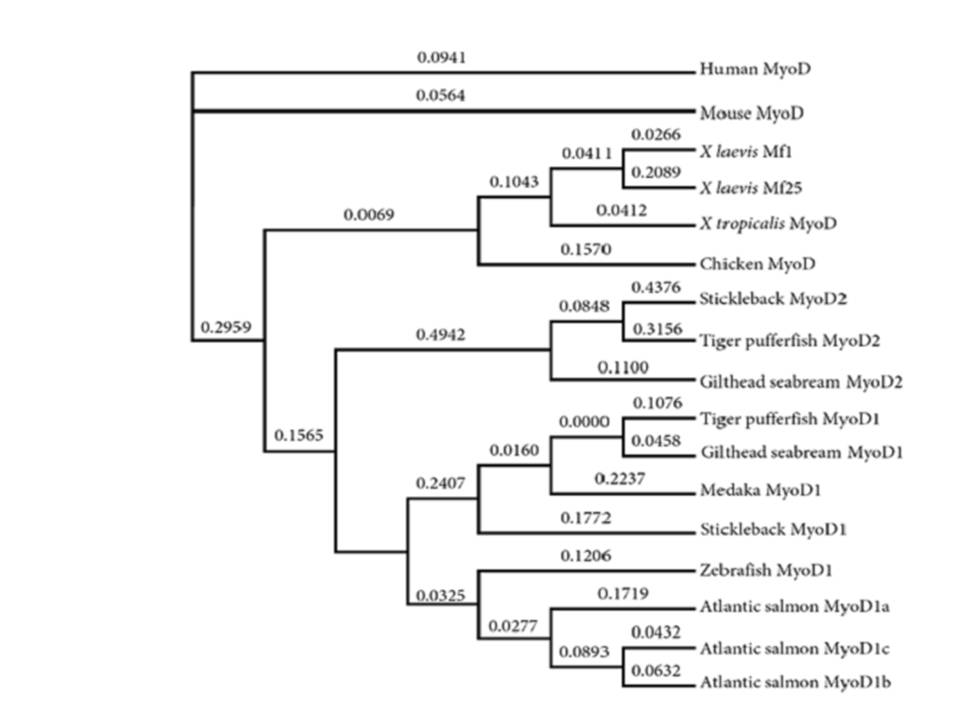
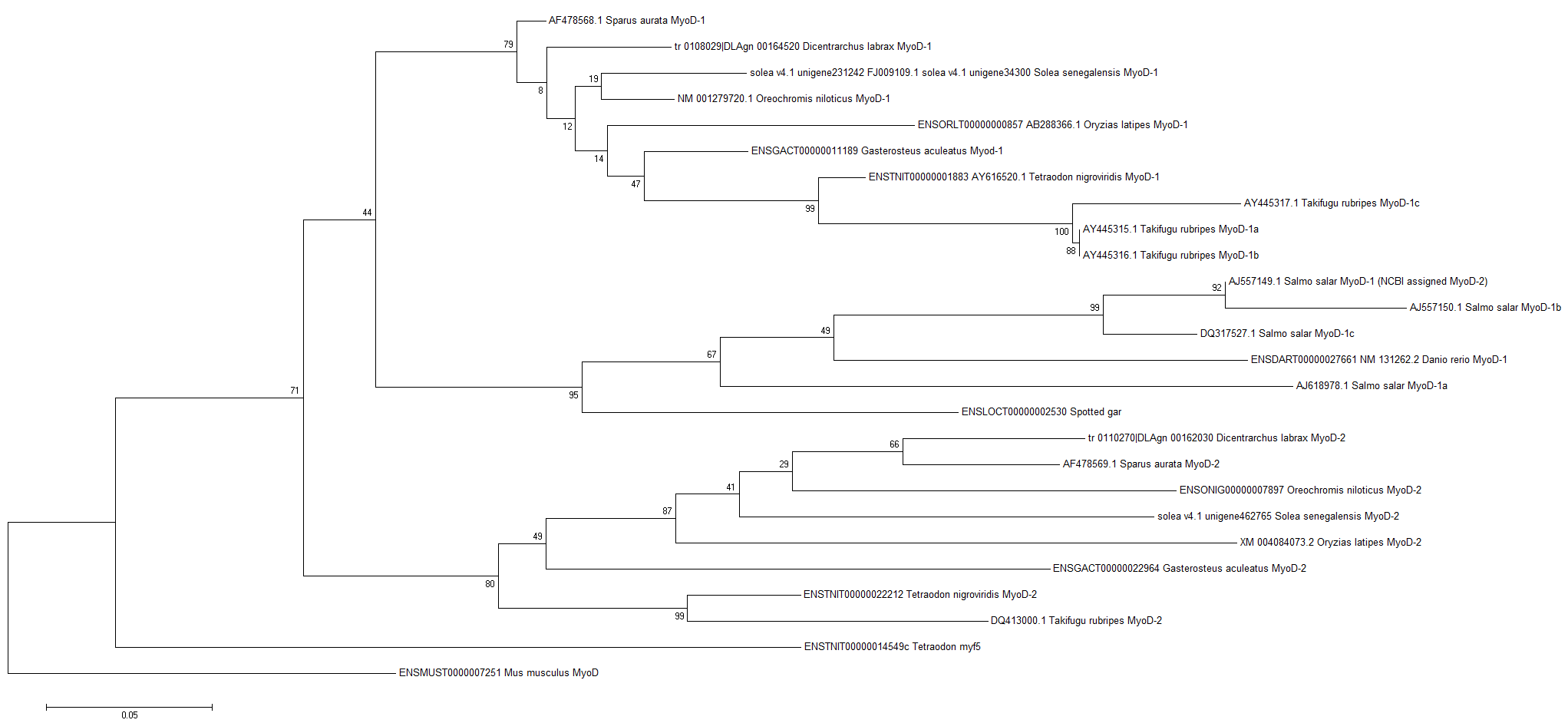
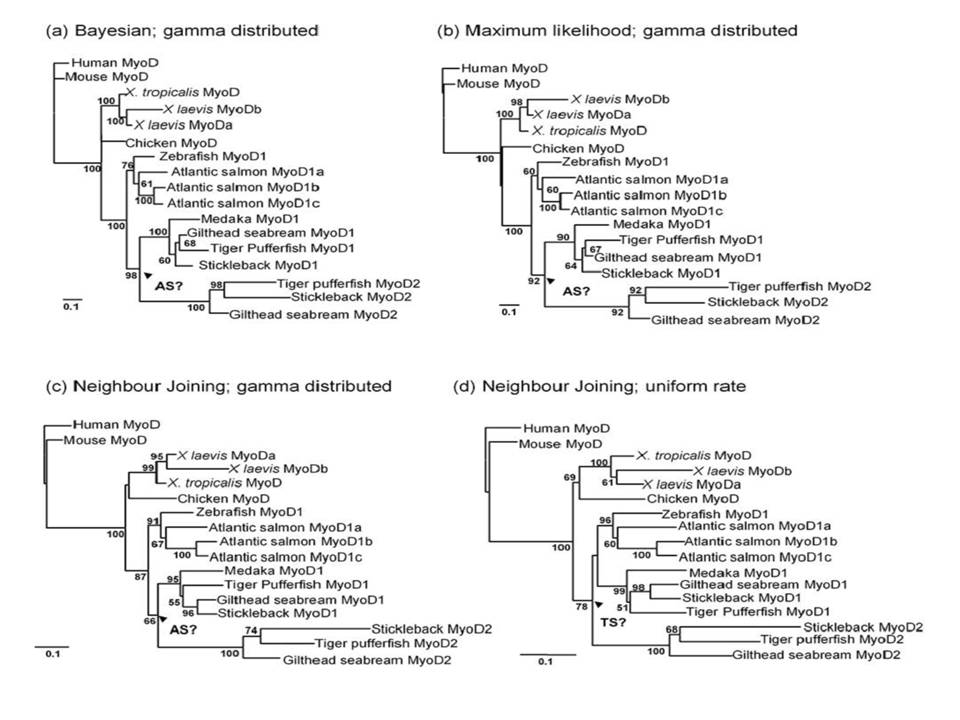
| Phylogeny | |||
| Genomic Map Locations | ON_Chr.7 MyOD-2 ON_GL831688 |
||
| Paralogs | |||
| Sequencing Methods | MyOD-2: Downloaded from ENSEMBL database. |
||
| Citations | |||
| Sequence | >NM_001279720.1 Oreochromis niloticus Myoblast determination protein-1 AGATCAGTTTGTGACAGGACTGTACATTCCCCCAAAAGCCCCGAATCCTGGTTCACGTTTCAGTTCTTCCCTAAAAAAGA GAGAAAAGTTTGGTCATAACTGGATTTTCTTCTTCCTGCTGTGTTCTGGACTGAACCATGGAGTTGTCGGATATCTCTTT CCCCATCCCCACCGCTGATGATTTCTATGACGACCCCTGCTTTAACACCAGTGACATGCACTTCTTCGAGGACCTGGACC CGCGGCTGGTCCATGTGGGGCTGTTGAAGCCGGACGACTCCTCCTCTTCATCCTCATCCTCCCCTTCCTCTTCTTCCTCC TCCCCGTCCTCCCTCCTGCATCTCCACCACCATGCCGAGGTGGAGGACGACGAGCACGTCCGCGCCCCCAGCGGGCACCA CCAGGCGGGCCGCTGCCTGCTCTGGGCCTGCAAGGCCTGCAAGAGGAAGACGACCAACGCAGACCGGCGGAAGGCGGCCA CGCTGCGGGAGCGCCGGCGGCTCAGCAAGGTCAACGACGCCTTCGAGACCCTGAAGCGCTGCACGACGGCCAACCCCAAC CAGAGGCTGCCCAAGGTGGAGATCCTGCGCAACGCCATCAGCTACATCGAGTCCCTGCAGGCGCTGCTGCGCGGTGGCCA GGAAGACGGCTTCTACCCGGTGCTGGAGCACTACAGCGGGGACTCGGACGCATCCAGCCCCCGCTCCAACTGCTCCGACG GCATGACGGATTTTAACGGCCCCACCTGTCAGACAACCAGAAGAGGAAGCTATGACAGCAGCTCTTATTTCTCCGAGACT CCAAACGGCGGTCTGAAGAGCGAACGCAGTTCAGTGGTCTCCAGTCTGGACTGCCTGTCCAGCATCGTGGAGCGGATCTC CACCGATAACAGCAGCCTGCTGCCGCCTGCTGACGGCCCAGGATCCCCGACGACGACGACAACTGTGCCGGTGGGTGAAG CAGGCACTGCCCCGGCGACCGCTCAGGTCTCTTCTCCGACTGCCAGCCAGGACCCCAACCTGATTTACCAAGTCCTATAG ACCCTCACACATACATATTCAACTCGGACATTACAAAAAAAAAAAAAAAA
>ENSONIG00000007897 Oreochromis niloticus Myoblast determination protein-2 ATGGATCTGTCAGACTTTCCCTTCGTTCTCTCTTCAGCAGATGACCTCTACGACCCCTGCTTCAGCACCAGTGACCTGAA CTTTTTTGATGACCTTGACACCCGGTTGATGCATGCCAGTTTTTTGAAGTCAGAGGACCATCTTCAGCACCACGTCCCCG TCACAGAAGAGGAGGACCAACATGTGAGGGCCCCTGGGGGCCTCCACCAGGCAGGTCACTGCCTGCTGTGGGCCTGCAAG GCCTGCAAGAGGAAGACAACCCATGCAGACCGGAGGAAAGCGGCGACCATGCGTGAGAGGCGACGACTCAGTAAAGTCAA CGATGCATTCGAGACACTGAAACGCTGCACAGCATCCAATCCAAACCAGAGACTGCCCAAGGTGGAGATCCTCCGCAATG CAATCAGCTACATTGAGTCACTACAGGCGCTGCTCAGGAACGGCCAGGATGATAGCTTCTACCCGCAGCTCGAACACTAT GGGAGTGACTCAGGAACCTCCAGCCCCCACTCCAACTGCTCTGATGGCTTGGTGGATTTTATCTCTCCGAGTTCAGCCAG AAGTGAAAACAGTGACGCTTCGTACTGCAGCCAGACAGCAGAGGATTGCAGCAGCAGCAGCAGTAAAACATCAGTCATTT CCAGTTTGGACTGTTTGTCCAGCATTGTAGAGAGGATCAGCACAGATCAGACTGCAGCCCCCCCTGGGGATAGCGTGGTC CCCCAAGGCCCTGGATCACCTCACACCGGCACTGCTATCTCCAATCTGTCTGCCGAGTCCAGCAACATTTGA
|
||||||||||
GO term(s)
Gene Expression
Gene Structure
Possible Primers
Synteny
Gene Domains
Molecular Markers
Data input by M.Iliopoulou
CLICK IMAGES
FOR LARGER SIZE