

| Organism | |||
| Phylogeny | |||
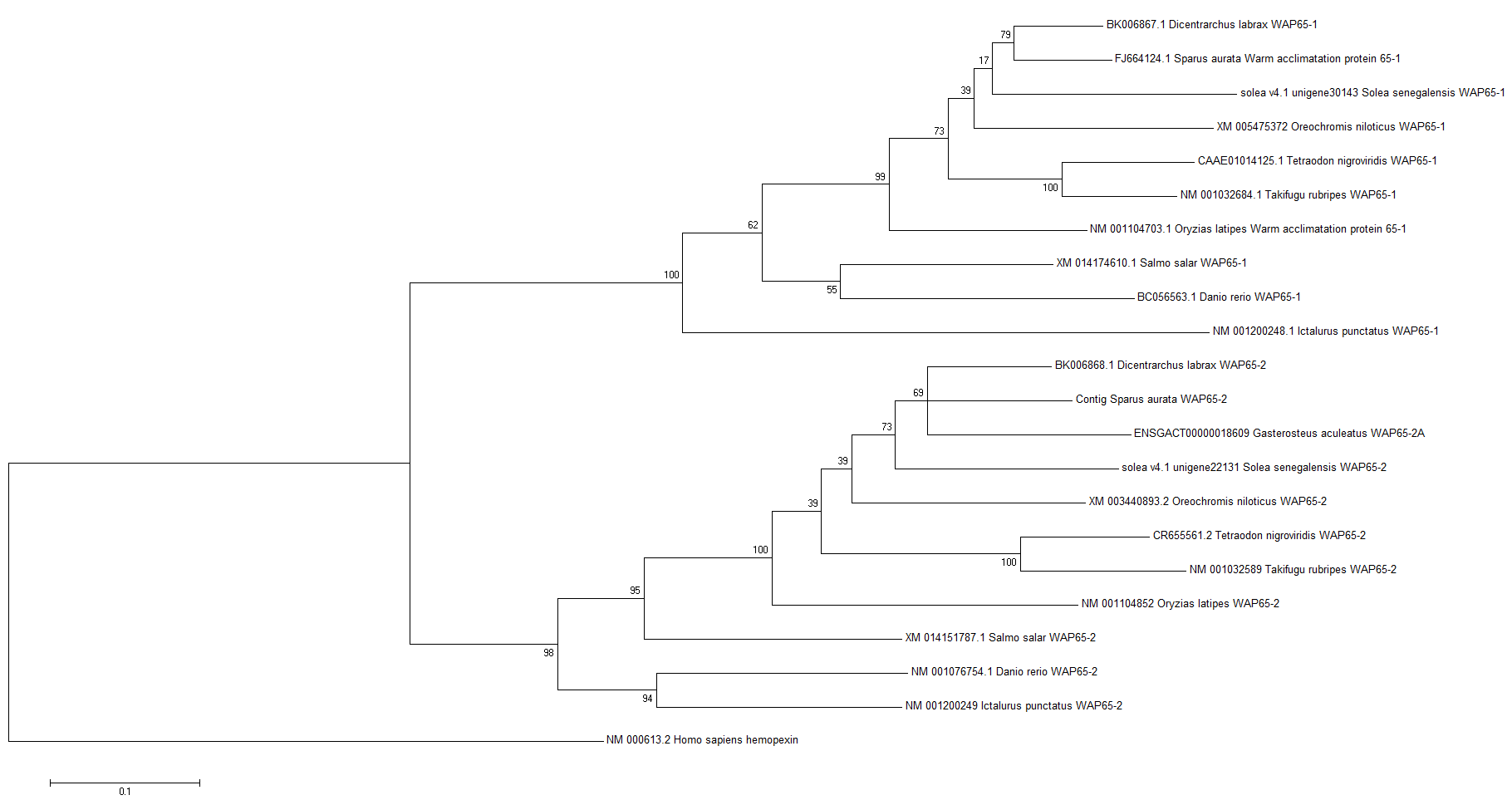
| Paralogs | |||
| Citations | |||
| Sequence | >NM_001032684.1 Takifugu rubripes Warm Acclimatation Protein 65-1 AACCTAATCCCCGGTTAGCTCTGTCCAGGCCTCTTCAGTGAAGGACAGGAAGCCATGAAGCTGCTCACCCAAGTGCTCTG CCTGGCCCTGGCTGTGACATGGGCTCATTGTAATAGCCATGCCTCAGCTGTACTTGATCGTTGCCTGGGTCTGGAGATGG ACGCTGTGGCAGTCAATGAAGTAGGAATCCCTTACTTTTTCAAGGGCGATCACCTGTTTAAGGGTTTCCATGGCAAAGCA GAGTTGTCAAATGAGTCCTTTGCTGAGTTGGATGACCACCACCACCTGGGCCATGTGGACGCTGCTTTCCGCATGCACTT TGAGAACAGCACCGACCACGACCACCTGTTCTTCTTCTTGGACCACAGTGTGTTCAGCTATTACCAGCACAAACTTGAAC AAGGCTACCCCAAAAAGATCTCTGAAGTTTTCCCAGGAATCCCCGACCACCTGGACGCTGCCGTGGAGTGTCCCCATCCA GAGTGTGAAGAAGACTCTGTCATCTTTTTCAAAGGAGATGAAATCTACCACTACAACGTCAGAACTCAGGCTGTAGATGA GAAAGAGTTCAAAGACATGCCAAACTGTACGTCCGCGTTCCGCTTTATGGAACACTTTTACTGCTTCCACGGACACATGT TCTCCAAGTTCGACCCCAAAACTGGGGAAGTGCTGGGCAAATACCCCAAAGAGGCCCGGGACTACTTCATGAGATGCGCC AAGTTCAGTGAAGAGAGCGATCCTGTGGAGAGAGAGCGTTGTAGCCGCGTTCACCTGGATGCCGTCACTTCTGATAACGC TGGAAACAAGTACGCCTTCAGAGGCCACCATTTCCTCTTTAAAGAAGAAGCTAATGACACACTGAAAGCCGACACCATTG AGAACGCCTTCAAAGAGCTGCACAGTGATGTGGATGCTGTTTTCTCCTACCAGGACCACCTTTACATGATCAAGAATGAT AAAATACATATCTATAAAACTGGAACTGCACACACTCACCTGGAGGGTTACCCCAAACCCCTGAAGGAGGAGCTGGGAAT CGAAGGCCCCATTGATGCTGCGTTTGTCTGCGGGGATCACCACATTGCTCACCTCATCAAAGGTCAGAAAATGTATGACG TTGATTTGAAGTCCAGCCAGCGTGTCGCAGATAATGAGCGCCCAATTTCGCTCTTCCAGAAGATCGATGCTGCCATATGT GATGGTGAAGGGCTGAAGGTGATCGTGGGCAACCATTACTACCACTTTGACAGCCCTATGCTATTTATAGCTGGGAGGGC CCTCCCTGAACAGCGCAGGGTATCTCTGGAACTGTTTGGCTGTGACCATTAAGATGTCAGGCTAACAGGGTAGAACTCTT GACAACAGCTACAACAACAAGCCGTCAATATAATAAAGCACCTCTGCCATCAAAGGGCTCAGCTGATGCAGTATATCGTG ACACTTGCCAACCTTTGCCAGTTTTACTTCTTTCGTCCTGTTTGAGCTTTGTGGTTTATGTGATTCTTCCTTTTGTGCTG TTGTTTGAAAGAACAGAAATAAACAAGGTTGAAGGTTG
>AB125933.1 Takifugu rubripes Warm Acclimatation Protein 65-2 ACAGCCAGACCCAGAGATCGTCACCATGGACCTCTTCAGCAAGACTCTGCTCCTCTGTTTGCTCCTCATCCTTACTGATG CAGCACCTGCGCCCCAAGATGCAGCAGAGAAAGACAACATTTCTGAAGTGAAAGAAGAAGATTCCGGTCCTGCTCTGCCA GACCGGTGTGCAGGAATTGAGTTTGACGCCATCACTCCTGACGAAAAAGGAAAGACTTTGTTCTTCAAAGGTGCCTACAT GTGGAAGGATTTTCATGGACCAGCACAGCTTGTCAGCGAGTCCTTCAAGGAAATTGACGACATTCCCAACGCTGGCAGCA TCAGTGCTGCCTTCCGAATGCACAACAAAGCCAATCCAGATGACCATGACCGCATTTACCTCTTCCTGGAAGACAAGGTG TTCAGCTATTATGAACAAGTCCTGGAAGAAGGCTATCCAAAACATATCAATGAGGAATTCCCTGGTGTTCCCACACACCT GGACGCAGCAGTGGAGTGCCCCAAAGGAGAGTGTATGGCTGATTCTGTTTTATTTTTCAAGGGACAGGATGTTCACATGT ATGATCTGAGCACCAAGACAGTGAAGACCAAGACATGGTCCCACCTGCCTGCTTGCACCTCTGCTTTTCGCTGGCTGGAG CACTATTACTGCTTCCATGGACACAACTTCACCAGGTTCAACCCAATATCTGGAGAGGTGAACGGAACTTATCCAAAAGA TGCCCGGCATTACTTTATGAGGTGTCCCAACTTTGGACACGGAGGTGGCTATAACATCCCTAAATGCAGTGAAGTTAAAA TAGATGCCATCACGGTTGATGAAGCAGGAAGAATGTATGCCTTTGCAGGACCCATCTACATGCGCCTTGACACTCGCCGG GATGGTTTTCATGCCTTCCCGATCACTCGGCAGTGGAAGGAGGTGGTTGGAAAAGTGGACGCGGTATTTTCCTACGGCGA CAAGATGTACCTAATCAAGGGTAAACAGGTTTACATCTACAAAGGCGGTGCTCACTACACCCTGGTTGAAGGCTATCCTA AGACCCTGGAAGAGGAGCTTGGGGTCGAAGGACCTGTGGATGCTGCTTTCGTGTGTCCGGGCCAGCACACGGTTCATATC ATTCAAGGAGAACGATTTCTTGATGTTTCATTAACGGCCACACCCAGGGTTGTTGCCCGAAACCTGCCCTTCGTTCTGTC CGACATTGATGCAGCCTACTGTGACGCAAAGGGAGTCAAGTTATTCAGCGGCTCCAAGTATTATCAATATGCCAGCGTCA CAATACTGGCTTTGAGCAAAATTGCTGCTCTTGCAGAACCTATAACCTCAGAAATGCTGGGATGCCAAGATTAACAATGT GTGTTGGCTTCACAAGACATAAATACAACAGCTAAAAATGATCAATACCAGTGCAAACAAAAACATACTGGAGCAAGAAG CCACCAGATCCTGTGCAGCCACTGTTGCGCAACAACAATTTATCATCAAATAAAATTTAAAAAATTTAAAAAAAACTA
|
||||||||||
GO term(s)
Gene Expression
Gene Structure
Possible Primers
Synteny
Genomic Map Locations
Sequencing Methods
Gene Domains
Molecular Markers
Data input by M.Iliopoulou
CLICK IMAGES
FOR LARGER SIZE