

| Organism | |||
| GO term(s) | Cellular Component: n/a Biological Process: n/a |
||
| Phylogeny | |||
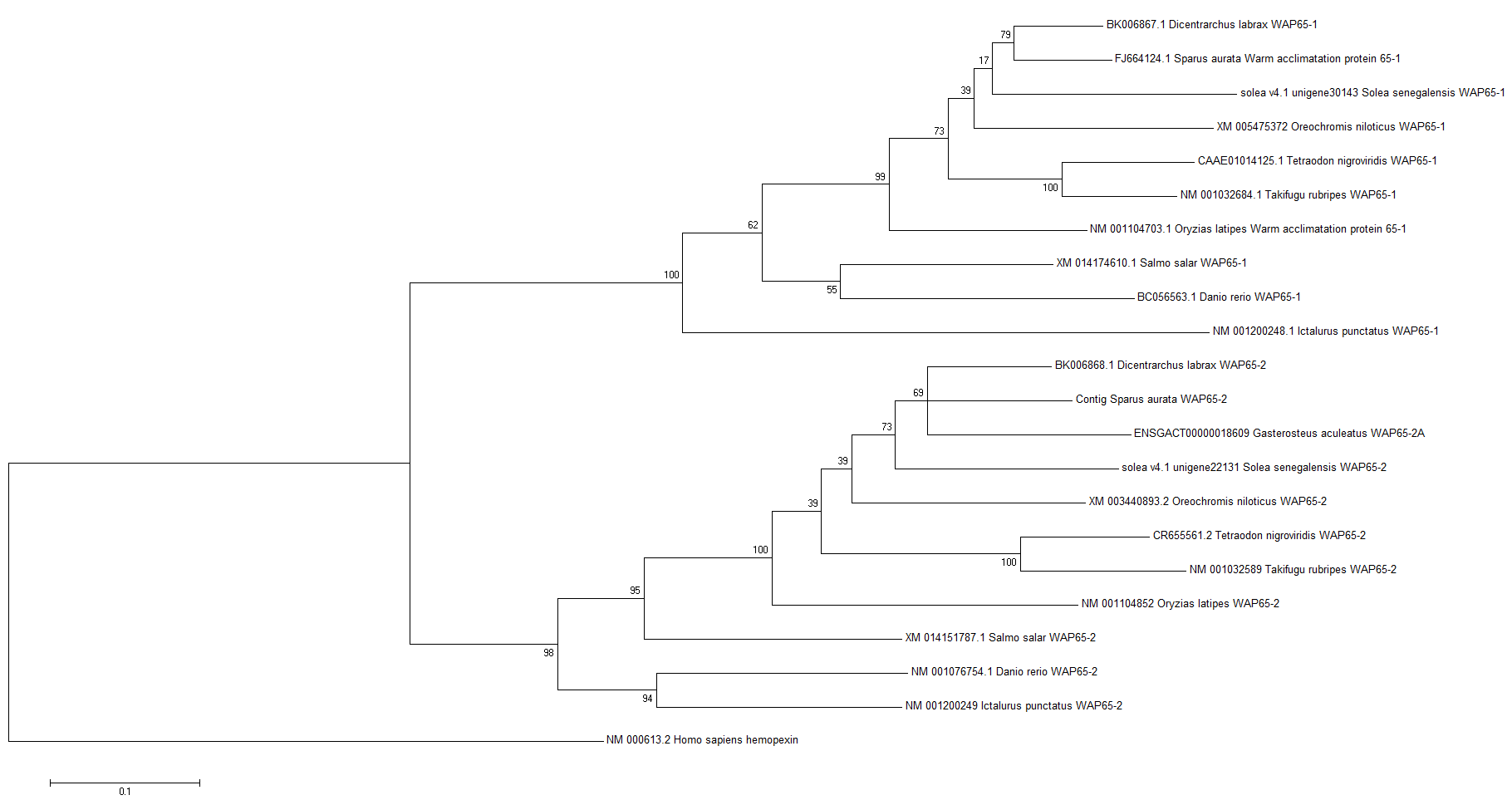
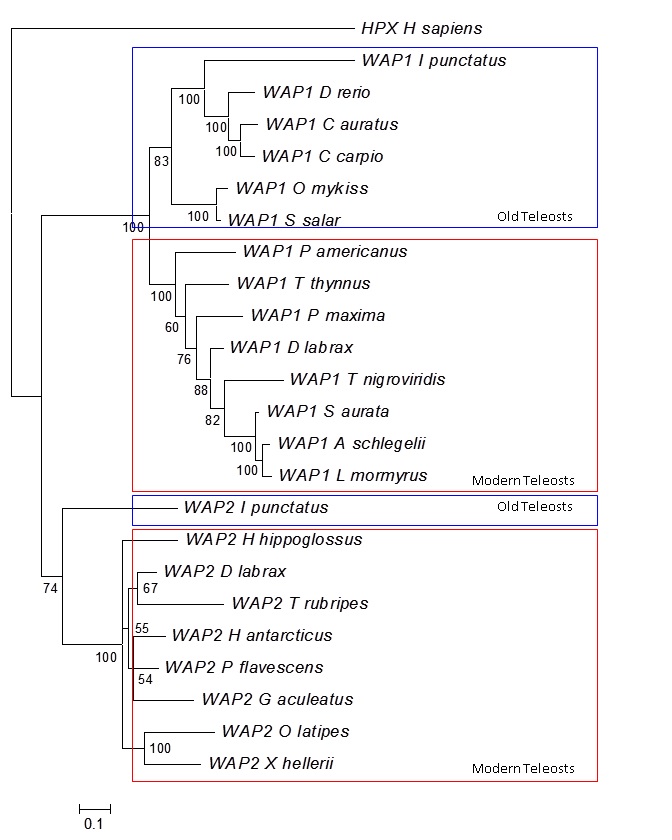
| Paralogs | |||
| Sequencing Methods | WAP65-1: Sanger sequencing |
||
| Citations | |||
| Sequence | >CR655561.2 Tetraodon nigroviridis WAP65-2 ATGCACAACAGCGCCAATCCGGATGACCACGACCGCATCTACTTCTTTTTGGATGACAAGGTGTTCAGTTACTATGACCA CGTCCTGGAAGACGGCTATCCAAAACACATCAGTGAGGAGTTTCCTGGTGTTCCCACACACCTGGACGCAGCCGTGGAGT GCCCCAAAGGAGAGTGCATGGCTGATTCAGTCTTGTTTTTCAAAGGACAAGAGGTTTCTGTGTATGATCTGAGCACCAAA ACGGTGAAGACCAAGACATGGTCCCACCTGCCTGCCTGCACCTCTGCTCTCCGCTGGCTGGAGCACTACTACTGTTTCCA CGGAAACAACTTCACTCGATTCCACCCCGTATCCGGAGAGGTGAACGGGACCTACCCGAAGGACGCCAGGCATTACTTCA TGAGCTGTCCCAACTTCGGACACGGAGCTGGCTACCAGCCCCCCGAATGCAGTAACGTCAAATTAGACGCCATCACGGCT GATGATGCGGGGAAAATGTATGCCTTTGCAGGGCCCATCTACATACGCCTGGACACCCGGCGCGACGGCATCCACGCCTT CCCCATCACCCGTTTGTGGAAGGAGGTGGCTGGAAGGGTGGACGCGGTGTTTTCCTACACTGACAAAATGTACCTAATCA AGGGAACACAGGTTTACATCTACAAAGGAGGCGCTCACTACACGCTGATTGAAGGCTACCCTAAAACCCTGAAAGAGGAG CTGGGGCTGGAAGGTCCTGTGGACGCTGCCTTTGTGTGTCCAGGTCAAGACGTAGTTCACATCATTCAGGGAAACCGAAT TCTTGACGTTTCCCTGACTGACACACCCAGGATCGTTACCCGAAACCTGCCCTTCGCCTTGACCGGCATCGATGCGGCCT ACTGCGACTCAGAGGGCGTTAAGCTGTTCATCGGCTCCAAGTATTACCACTACCAGAGTGTCACAGTGATGGTTTTGGGC AAAATTGCCGCTATTGCAAAACCGATAACCTCAGAAATGATGGGCTGTCGAGATTAG
>CAAE01014125.1 Tetraodon nigroviridis Warm Acclimatation Protein 65-1 ATGAAGCTGCTCACCCACATGCTCTGCCTGGCCCTGGCTGTCACCTGGGCTCATGGGGATAGCCATGGCCTAGCCAAACT CGACCGGTGCCAGGGCCTGGAGATGGACGCGGTTGCCGTCAACGAAGTAGGAATCCCATACTTTTTCAAAGGCGATCACC TGTTCAAGGGTTTCCACGGCGAAGCGGAGCTGTCAAACGAGACCTTTGCCGAGTTGGATGACTACCATCACCTGGGCCAT GTAGACGCCGCTTTCCGCATGCACTTTGAGAAAAGCACCGACCATGATCACATGTTCTTCTTCCTGGACCACCAAGTGTT CAGCTACTACAAGCACAAACTTGAAGACGGCTACCCCAAAACCATCCACGACGTCTTCCCGGGAATCCACGGCCCCCTGG ACGCCGCTGTGGAGTGTCCCCATCCAGAGTGTGACGAAGACTCGGTCATCTTTTTCAAAGGAAAAGAAATCTTCCACTAC AATGTCAGGACGAAGGCAGTGGATGAGAAGGAGTTCAAGGACATGCCAAACTGCACGTCTGCTTTCCGCTTCATGGAACA CTTTTACTGCTTCCACGGTCACATGTTCTCCAAGTTTGACCCCAAAACCGGGGAAGTGCACGGCAAATACCCCAAGGAGG CACGAGACTACTTCATGAGATGCTCCAATTTCAGTGCAGAGAGCGACCACCTGGACAGAGAGCGCTGCAGCCGCGTCCAC CTGGATGCCATCACCTCCGACGACCCTGGAAACATGTACGCCTTCAGAGGCCACCACTTCCTCCGCGAAGACACCAATGA CACACTGACAGCTGACACCATTGAGAGCGCTTTCAAAGAGCTGCACAGTGAGGTGGATGCCGTTTTCTCCTATCAGGATC ACCTTTACATGATCAAGGATGATGAGCTCTATGTCTACAAAACGGGAGAGCCTCACACTCACCTGGAGGGTTACCCCAAA CCTGTGGAGGCGGAGCTGGGAATCCAAGGCCCCATTGATGCTGCGTTTGTCTGCGAGGATCATCACATTGCTCACATCAT CAAAGGTCAGAAAATGTATGATGTGGACCTGAAGTCCAGCCCTCGCGTCGCAGGCATCGAGCGCCCGATTTCGCTCTTCA GCAAGATCGATGCCGCCATGTGTGATAGTGAAGGCGTGAAGGTGGTGGTGGGCAACCATTTCTACGTCTTTGCTAGCCCC ATGATCTTTAGCACCGCAAGGATCCTCCCCGAGCAGCGCAGGGTGTCCCTGGAAATGTTCGGCTGTGACCACTGA
|
||||||||||
Gene Expression
Gene Structure
Possible Primers
Synteny
Genomic Map Locations
Gene Domains
Molecular Markers
Data input by E.Sarropoulou
CLICK IMAGES
FOR LARGER SIZE