

| Organism | |||
| GO term(s) | Biological Process: GO: 0006810 |
||
| Phylogeny | |||
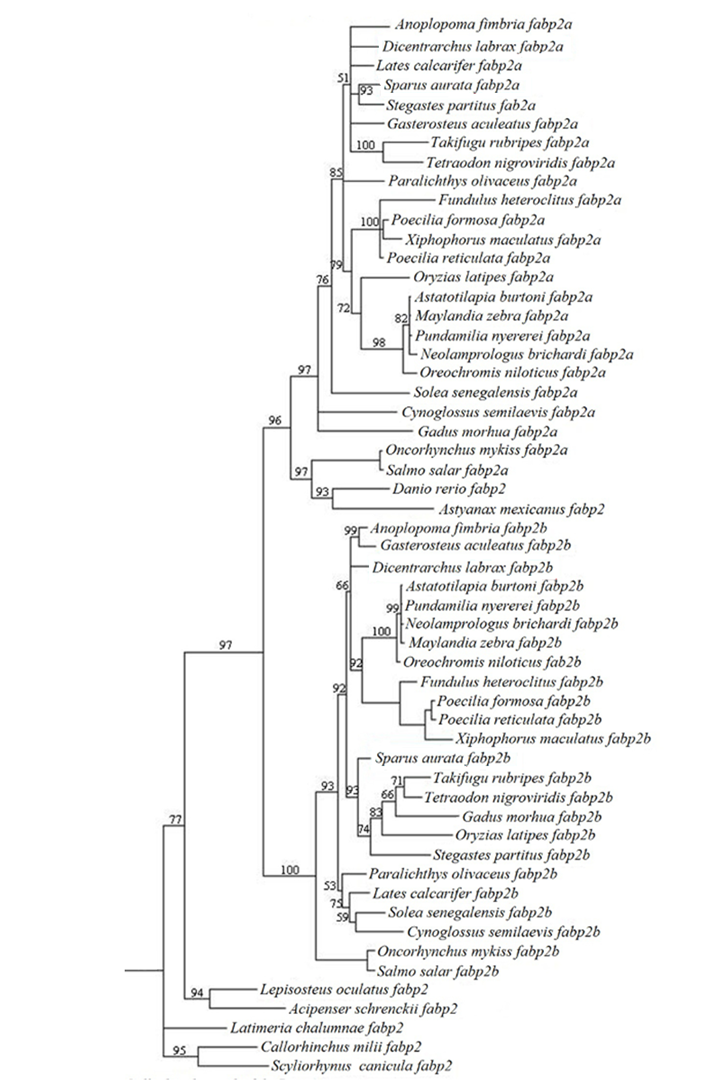
| Paralogs | |||
| Sequencing Methods | fabp2b: MODEL REFSEQ: This record is predicted by automated computational analysis. This record is derived from a genomic sequence (NW_014445096.1) annotated using gene prediction method: Gnomon. |
||
| Citations | |||
| Sequence | >XM_004549487.2 Maylandia zebra fabp2a GTGATTTAAAAGGAGCGGCAGAGTTTGAAAAGGGCACTCCTTGTTGCAGAGTCCTCCAGCTCACCCTCACCGCCACCATG ACTTTCAACGGCACCTGGAAAGTTACTCAAAATGAGAACTATGACAAATTCATGGAAAAAATGGGAGTTAACATGGTGAA GAGGAAGCTGGCTGCTCACGACAACCTCAAGATTACCATCACACAGGAGGGAGACAAGTTTAACGTCAAGGAGAGCAGCA CTTTCCGCAACATCGAAATTGAATTTACCCTCGGAGTCACCTTTGAGTACGCCCTTGCAGATGGAACAGAACTATCAGGT GCGTGGACCTTGGAGGGAGACGTGTTGAAGGGAATTTTCAAGAGAAAGGACAACGGAAAAGACCTGACGACAACCAGAAT TGTTCAAGGAGATGAACTCATACAGAGCTACACCTACGAAGGTGTGGATGCAAAGAGGATTTTCAAGAGGAGTTAGACCA AATCCATCTAAAGAACCGAATTGAAATATTTTCAGGGTTACATACAGTTTTGTGCCAAGTCATCAACAACATGTAACTCA TCATATTTTAATAGCTGTATTAATAAAGTCACAACTGCCTATTAA
>XM_004554477.1 Maylandia zebra fabp2b TTTATCAGCGTATCCTTGAGGTCATGCAGCTATCGGCCTACATTTGACACCGTCTTTAAATGGCCACATCAGCAGACAGA TAATCAGTGAGATAAAGAACAGCATCTTCCATGCCAGCTCAAGGAGGGGTGGATGTGTATAAATTGAGGCCTTTGGGGAA TCACAATCTCACGGTCTGCTGTAGCGCTTCATCATCAGCTGCCTTCAACCCGACGAGCCTGCAGCCATGTCCTTTAATGG AACCTGGAAGATCGACCGCAGTGAGAACTATGTCAAGTTCATGGAGCAAATGGGTGTTAATCTTGTGAAACGCAAGGTGG CAGAGCACGACAACCTGAAGATCACCATCGAGCAGAACGGGGACAAGTTTCACGTCAAAGAGTCCAGCACTTTACGCACC AAAGAGGTTGACTTCACTCTGGGGGTTCCGTTTGACTACACCCTGGCTGATGGCACTGAAGTCTCAGGTGCATGGGAGAT GGAGGGGGACATGATGAAAGGCAAATTCACCAGGAAAGACAACAACAAGCTCCTGACCACTACTAGAACTCTGGTGGGCG GAGAGCTCGTGCAGAGCTACAACTATGAAGGGGTGGATGCCAAGAGGATTTTCAAGAAGCAGTAACCTGGATATTGAAGT TCAAATTTTATTTTTATATAAATCACACAGCCCAGTGAACTGTATCTGAAGTTATTGTTGGCATTTAGCTTATTTTACAA GAAGAATTATGGTCACCATGTTCATGAAACACTGAAATGGTCACACAGCGCAGTTAAATTTGCATCCCTTTTCCTGTGAA AGGAGAAAACAAACACTAAACAGCATCCTGGCAGTGGATATCTATCTGTAGCAGTAGCTAAACATTCAAATGGGTTTAGT TTTATTTGTCTTGGAGGGGTTCGGGATTTTCCGCACATCATAGTTTCAACAAATTTCACAGGACTCATTCATTGGTATGG TGTAGGTTATCCACAGTAATGGCTGTTTTCAGGTAAAGCTCCACAGCAACATGAAATACATGAAATGTTATTGTGTGTGT TCAAACAGGGGGAAAAAATCAAATTGCACTAATGGTTCTCATGTATCAGATTGTCCTCTACAATAAAGCATGTTTATTAT GTCACTTGA
|
||||||||||
Gene Expression
Gene Structure
Possible Primers
Synteny
Genomic Map Locations
Gene Domains
Molecular Markers
Data input by Elisavet Kaitetzidou
CLICK IMAGES
FOR LARGER SIZE