

| Organism | |||
| Phylogeny | |||

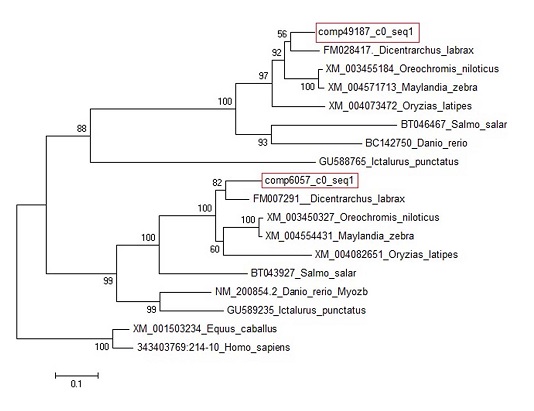
| Paralogs | |||
| Sequencing Methods | MYOZ-2aII: Downloaded from ENSEMBL MYOZ-2b: BioProject: PRJNA183868 |
||
| Citations | |||
| Sequence | >XM_004082651 Oryzias latipes Myozenin-2aIProtein ATGTCTCGGTTCACCACCATGACAACAAGGGAAAGGAAAATGCAGGCGGCAGCAATCTGCAGGGAGGTGCATGCTCAG GATGAGTTTTCGATGGATCTTGGGAAGAAAATGAGCGTGCCCAAAGACATCATGCTCGAGGAGCTTTCCCTTGCCTCCAA CCGTGGGTCCCGACTCTTCAAACTGCGCCAGAGACGCTCAGAAAAGTACACTTTTGAGAATGTCCACAATCAAAACAACA TGCAATTAAATAACAACGCAATTCCTAAGTCTGAGAATGAGACTACCACATTCACCAACGGCAACGAGGACAACTCTAGA ACCAACCAACCATATAAAGTCACAATTGACACACTGGACACAAAAATGATACCAAACCCAGGCATTATTGCTCCAGGATA TGGAGGTCCTTTGAAAGACATCCCTCCAGAGAAGTTTAACAGTACAGCTGTGCCGAAGTCATACCGCTCACCCTGGGAGC AGGCCATTATCAACGACCCAGCATTGGCTGACACACTAATTACCCGAATGCCTCACACAAAGCCTCAAGCAGAATGTCCA GGATACAAGAGCTTCAACAGAGTCGCAACCCCTTTTGGTGGATTCATCAAAGCACCCCGGCCAGTTCCTGACAATCAACT TCAGGTGGAAACCTTCCCAGACCTCCAAGCACTTCAGGACGATGGTGGGCTACATCGACCATCCTTCAACAGATCTGCTC TGGGCTGGACGTCAACTGCCAGCCCAGCCGCACTCCCAACTGTTTGCCCGGAGCTTGTTCTCATCCCTGAGTCAGAAGAC CTTTGA
>ENSORLG00000019473 Oryzias latipes Myozenin ATGGATCTCGGAAAGAAGCTCAGCACTCCAAAAGACATCATGTTGGAGGAGCTATCGCTGCTTTCCAACAGAGGCTC TCGCCTGTTCAAAATGCGGCAGAGGAGATCAGAGAAATACACTTTTGAGAGTATTCAAAATGAAACAAACGCGCTGCTGA CTAATGATATTCTAAATCGAAACAATATAGATTTTATGGTGGATCCGTCAACTCAGGGAGACCAAAATGCAAACAATCCT GCTTCAGATACGAGCCAAGAAAAATCAGACAGCACGGGCGTGCACAAGACCTATCACACGCCATGGGAGGAGGCCATCCT CAGTGACCCTGACCTCGCTGAAACCATCAAACTCAGAATGCCAGAACCAAACCCACAACCAGAGCTTCCACAGTTCAGAT GCTTTAATAGGGTTGCAACCCCTTATGGTGGCTTTGACAAAGGTCCCAGAGGAATCACTTTCAAGCTCCCCGAGGTGGAC CTGAACCTACCACGATTCCCAGAGTTGAACGAGTCAAGGATGAAGAGGCCCACCTTT
>XM_004073472_Oryzias latipes ATGCAGTCGGGCCTGGGTGACGTGACAAAACAGAGGATGTTACAGGCACAAGCCCTTGCTAATGAAGCCAGAGGAGGC CTGAACCTGGGGAAAAAGATCAGCGTTCCAAAAGACGTGATGATGGAGGAGCTCAACCTTCCCTCCAATCGCGGCTCTCG CATGTTTCAGGAGAGACAGAGGAGAGTAGATAAGTTCACTCTGGAGAACGTCACCTCTGGACCTCATTACACCAATGTTC ACCTCGAGGCCAGTCCTCCCCAGCAGACAGTGGTGCAGCCGCAGGGAGGAAAAGAAAACCAAGCTGTCTCCATCCCCGGA TATTCTGGACCTTTGAAGGAAATTCCCCATGAGAAGTTTAACACAACCATAATCCCCAAATCTTACTGCTCCCCATGGAG GGAAGCTTTGGGAGGCAATGAGGAGCTTTTGGGTCTCCTAAACACACAGCTGCCACAGCCCCCACAAAAACTACAGCCTG CCAACTACAGGTGTTTTAACAGGTCTCCGATGCCATTTGGGGGCTCTACGGCAAGCAGGAGAGTGATCCCAGTCATTTCC TTTGAGGCAGTGGCGTCCCAGAACCTTCCCAACGTCTCTATGGACCACATGTGTCGACGGCCCAACTTCAACAGAGCTCC CAGGGGATGGGGAGGGAACTACAGCCCGGAATCAAATGAACTATGA
|
||||||||||||||
GO term(s)
Gene Expression
Gene Structure
Possible Primers
Synteny
Genomic Map Locations
Gene Domains
Molecular Markers
Data input by Mara Iliopoulou
CLICK IMAGES
FOR LARGER SIZE