

| Organism | |||
| GO term(s) | Cellular Component: GO:0097452 Biological Process: n/a |
||
| Gene Structure | |||


| Phylogeny | |||

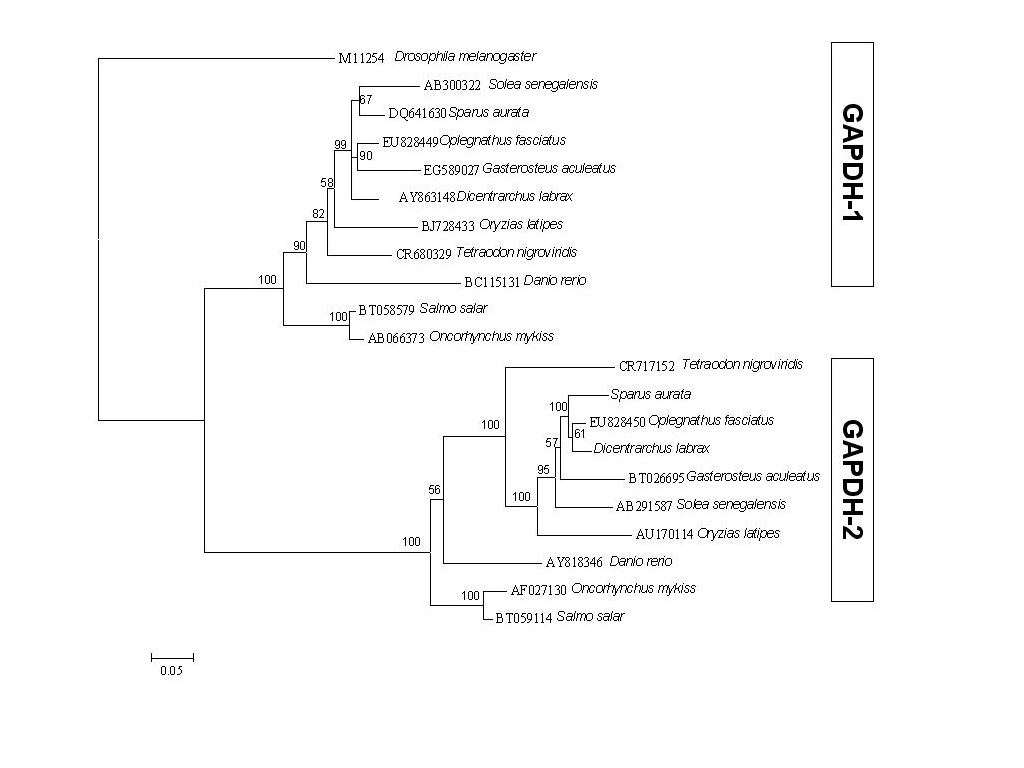
| Paralogs | |||
| Citations | |||
| Sequence | >CR680329 Tetraodon nigroviridis Glyceraldehyde-3-phospate dehydrogenase-1 ATGGTCAAAGTTGGCATCAACGGATTCGGCCGCATCGGCCGTCTGGTGACCCGCGCTGCCTTCACCTCCAAGAAGGTGGA GATTGTGGCCATCAATGACCCCTTCATCGACCTGGAGTACATGGTCTACATGTTCAAGTATGACTCCACCCACGGCCGCT ACAAGGGTGAGGTGAAGGCTGAGGGTGGCAAGCTGGTCGTCGATGGACATGCCATCACCGTTTTCCACGAGAGGGACCCT GCTAACATCAAATGGGGTGAGGCTGGTGCCCAGTATGTGGTTGAGTCCACTGGCGTGTTCACCACCATCGAGAAGGCCTC CGCCCACTTGAAGGGTGGTGCTAAGAGAGTGATCATCTCTGCACCCAGTGCCGACGCCCCCATGTTTGTCATGGGCGTCA ACCATGAGAAGTACGACAATTCCCTTGCTGTTGTCAGCAACGCTTCCTGCACAACAAACTGCCTGGCTCCCCTGGCCAAG GTCATCAACGACAACTTCGGCATCATTGAGGGCCTGATGAGCACAGTTCACGCCATCACCGCCACCCAGAAGACCGTGGA CGGCCCCTCGGGCAAGCTGTGGAGAGACGGCCGCGGCGCCAGCCAGAACATCATCCCCGCCTCCACCGGCGCTGCCAAGG CTGTCGGCAAGGTCATCCCCGAGCTGAACGGCAAGCTGACCGGCATGGCCTTCCGCGTTCCCACCCCCAACGTGTCTGTG GTGGACCTGACGGTCCGCCTGGAGAAGCCCGCCAAGTATGAGGACATCAAGAAGGTGGTGAAGGCGGCAGCAGATGGGCC CATGAAGGGCATCCTGGGATACACGGAGCACCAGGTTGTGTCCACAGACTTCAACGGCGACAGCCACTCCTCCATCTTTG ATGCCGGCGCCGGTATCGCCCTCAACGACCACTTCGTCAAGCTGGTCACATGGTACGACAACGAGTTCGGATACAGCAAC CGCGTGTGCGACCTGATGGCCCACATGGCTGGAAAGGAGTA
>CR717152 Tetraodon nigroviridis Glyceraldehyde-3-phospate dehydrogenase-2 ATGTCAGAGCTCTGCGTTGGAATCAATGGCTTTGGGCGTATTGGCCGCCTGGTCCTGAGGGCTTGCCTGGAGAAAGGCAT AAAGGTGGTGGCCATCAACGACCCCTTCATCGACCCGGAATACATGGTCTACATGTTTAAATACGACTCCACTCACGGCC GTTTCAAGGGCGAAGTCAGTCAGGAGAATGGCAAGTTGGTCGTAGATGGCCAGTCCATCTTCGTTTACAAGTGCATGAAG CCAGCTGAGATCCCCTGGGGCGATGCTGGAGCCAAGTATGTGGTTGAATCCACTGGAGTCTTCCTCAGCACGGAGAAGGC CGGCGCTCACCTCCAAGCTGGTGCTAAGCGTGTGGTTGTGTCCGCTCCATCACCCGATGCTCCGATGTTCGTCATGGGTG TTAACGAGGACAAGTATGACCCCTCCAGCATGACCATTGTCAGCAACGCCTCCTGCACCACCAACTGCCTGGCCCCCTTG GACAAAGTCATCCACGACAACTTTGGCATCGAGGAGGGTCTGATGACTACGGTCCACGCTTACACGGCCACTCAGAAGAC GGTGGACGGCCCCAGTGGCAAGGCCTGGCGCGACGGCCGCGGNGCCCACCAGAACATCATCCCTGCTTCCACCGGTGCCG NCAAGGCCGTGGGCAAGGTCATCCCTGAACTCAACGGCAAGCTGACAGGCATGGCTTTCAGGGTGCCAGTGGCTGACGTG TCGGTGGGTGGACCTGACCTGCCGGCTGTCCAAGCCTGCGTTTTACGCCCCATCAAGGAGCCCTCAAGAAGCCGCCACGG ACCCCAGAAGGGAGTGCTGGGTTACACGGAGGACCAGGTGGTGTCCTCTGATTTCAGCGGGGACTCTCACTCCTCCATCT TTGATGCTGGCGCTGGCATCTCCCTTAGCGACAACTTTGTCAAGCTCATTTCCTGGTATGACAATGAGTATGGCTACAGC CACCGCGTAACTGACCTGCTGCTGTACATGCACGGAAAGGAGTA
|
||||||||||
Gene Expression
Possible Primers
Synteny
Genomic Map Locations
Sequencing Methods
Gene Domains
Molecular Markers
Data input by M.Iliopoulou
CLICK IMAGES
FOR LARGER SIZE