

| Organism | |||
| GO term(s) | Cellular Component: GO:0097452 Biological Process: n/a |
||
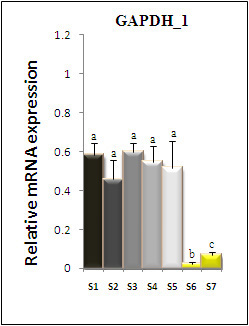
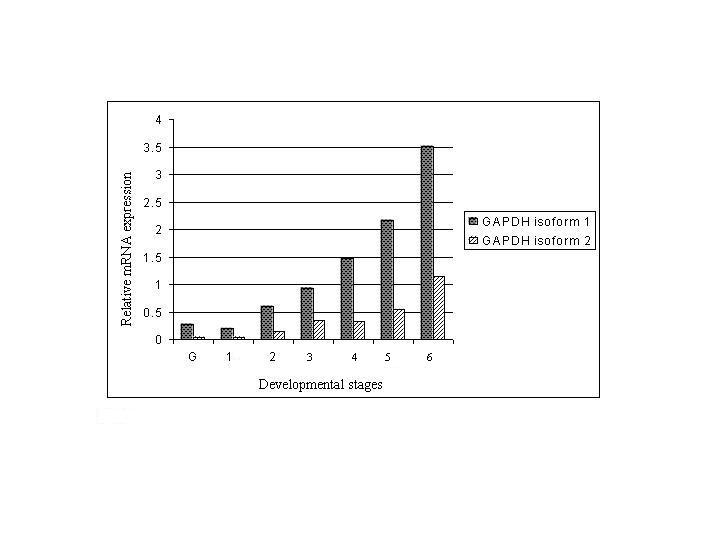
| Gene Expression | |||
| Gene Structure | |||


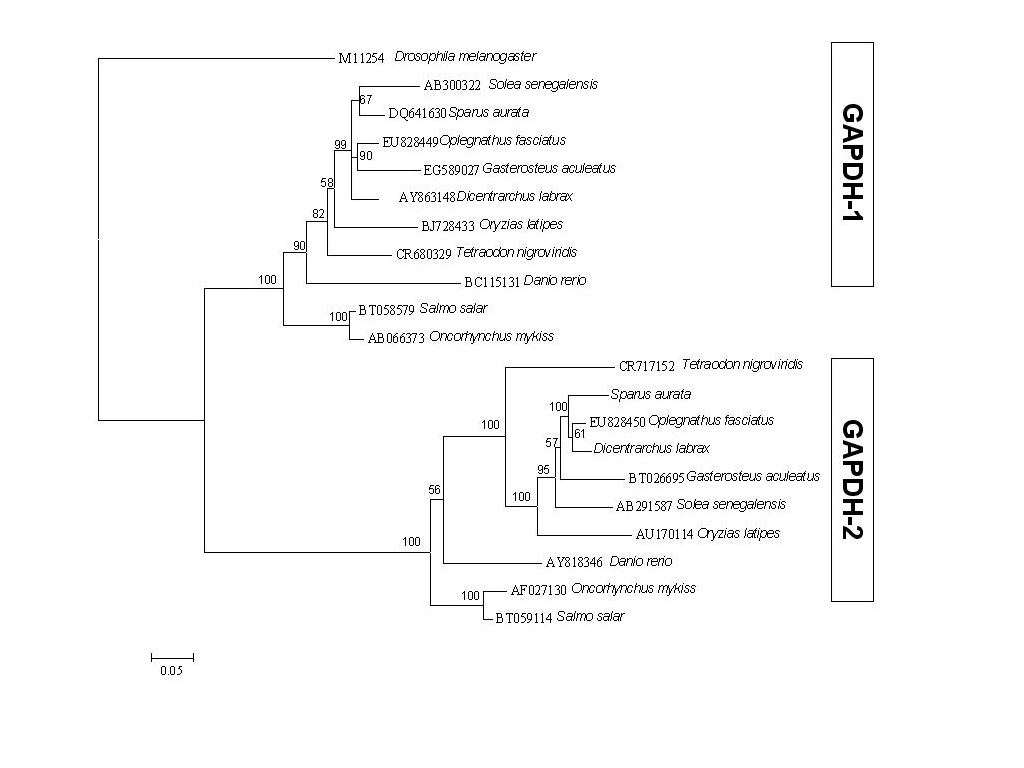
| Phylogeny | |||

| Synteny | |||
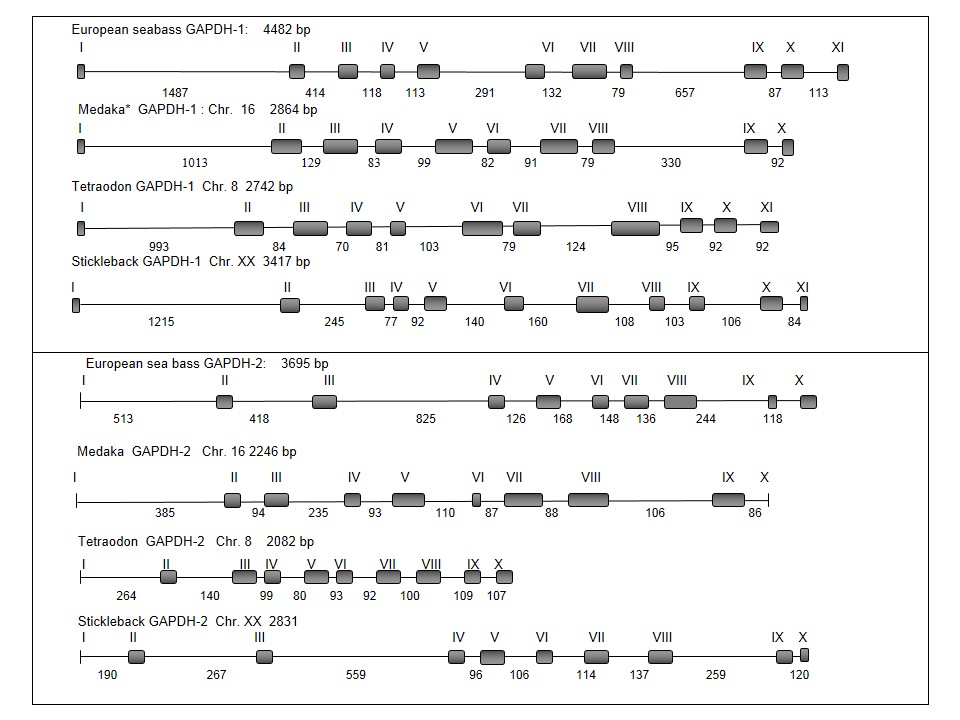
| Paralogs | |||
| Sequencing Methods | GAPDH-2: Assembly of homologous sequences of the gilthead sea bream for each gene were retrieved from the NCBI non-redundant (nr) or EST database. |
||
| Citations | |||
| Sequence | >DQ641630 Glyceraldehyde 3-phosphate dehydrogenase ATGGTGAAAGTCGGTATCAATGGATTCGGCCGCATCGGTCGTCTGGTGACCCGTGCTGGCTTCACCTCCAAGAAGGTGGA GATTGTGGCCATCAATGACCCCTTCATCGACCTGGAGTACATGGTCTACATGTTCAAGTATGACTCCACCCACGGCCGCT ACCATGGCGAAGTCAAGATTGAGGGCGACAAACTTGTCATCGACGGACATAAAATCACTGTTTTCCACGAGAGGGACCCA GCTCACATCAAATGGGGTGATGCTGGTGCCCAGTACGTTGTTGAGTCCACTGGTGTGTTCACCACCATTGAGAAGGCCTC TGCTCACTTGAAGGGCGGTGCCAAGAGAGTCATCATCTCTGCACCCAGCGCCGACGCTCCCATGTTTGTCATGGGTGTCA ACCATCAGAAGTACGACAAGTCACTCCCAGTGGTCAGCAACGCCTCCTGCACAACCAACTGCCTGGCCCCCCTGGCCAAG GTCATCAACGACAACTTCGGCATCATTGAGGGTCTGATGAGCACAGTTCATGCCATCACTGCCACCCAGAAGACCGTGGA CGGCCCCTCCGGCAAGCTGTGGAGGGACGGCCGTGGTGCCAGCCAGAACATCATCCCCGCCTCCACCGGTGCTGCCAAAG CTGTCGGCAAGGTCATCCCCGAGCTCAACGGCAAGTTGACCGGCATGGCCTTCCGTGTCCCCACCCCCAACGTGTCAGTG GTTGACCTGACAGTCCGCCTGGAGAAACCTGCCAAATACGATGACATCAAGAAGGTCGTCAAGGCTGCAGCTGAAGGACC CATGAAGGGCATCCTGGGATACACAGAGCACCAGGTCGTCTCCACAGACTTCAACGGTGACAGCCACTCCTCCATCTTTG ATGCTGGCGCTGGCATCGCCCTCAACGACCACTTTGTCAAGCTGGTCACATGGTACGACAATGAGTTCGGCTACAGCAAC CGTGTCTGCGACCTGATGGCCCACATGGCCTCCAAGGAGTAG
>Sparus aurata glyceraldehyde 3-phosphate dehydrogenase-2 ATGTCAGATCTCTGTGTTGGAATCAATGGCTTCGGTCGTATTGGCCGTCTGGTCTTGAGGGCTTGCCTTCAGAAGGGCAT CAAGGTTGTGGCCATCAATGACCCCTTCATTGACTTGAAGTACATGGTCTACATGTTCAAGTATGACTCCACCCACGGCC GTTACCATGGTGAGGTCAGTGAAGAAGATGGCAAGCTCATGGTCGACGGCAACGCCATCGCTGTCTACCAGTGCATGAAG CCAGCAGAGATCCCCTGGGGCGATGCTGGAGCCAAGTACGTTGTTGAGTCCACTGGAGTCTTCCTCAGTGTGGATAAGGC CAACGCTCACATCCAGGGTGGAGCACAGCGTGTGGTTGTGTCCGCCCCCTCACCCGATGCTCCAATGTTTGTCATGGGAG TTAATGAGGAGAAATATGACCCGGCCACCATGAAGATCGTCAGCAATGCCTCCTCCACCTCCCACTGCCTGGCCCCCCTG GCCAAAGTCATCCATGATAACTTTGGCATTGAGGAGGCTCTCATGACTACAGTCCATGCATACACAGCCACCCAGAAGAC AGTGGATGGTCCCAGCGCCAAGGCCTGGCGTGATGGCCGTGGTGCCCACCAGAACATCATTCCAGCCTCCACTGGTGCCG CCAAGGCAGTCGGCAAAGTTATCCCCGAGCTCAATGGTAAGCTGACAGGCATGGCCTTCAGGGTGCCAGTGGCTGATGTG TCAGTGGTGGATCTGACATGCCGTCTGTCCAAGCCTGCATCTTACGCTGAGATTAAGGAAGCCTGCAAGAAGGCCGCACA TGGGCCCATGAAGGGAGTGCTGGGTTACACCGAGGACTCTGTGGTGTCCTCTGACTTCATCGGTGACACCCACTCCTCAA TCTTTGATGCTGGCGCTGGCATCTCCCTCAACGACAACTTTGTCAAGCTCATTTCCTGGTATGATAATGAGTCCGGCTAC AGCCACCGTGTTGCTGACCTCCTGCTGTACATGCACTCCAAGGACTA
|
||||||||||
Possible Primers
Genomic Map Locations
Gene Domains
Molecular Markers
Data input by E.Sarropoulou
CLICK IMAGES
FOR LARGER SIZE